
Digitalisaatio
Digitalisaatiolla tarkoitetaan yhteiskunnan ja talouden digitaalista muutosta. Se kuvaa siirtymistä analogisten teknologioiden leimaamasta teollisesta aikakaudesta tiedon ja luovuuden aikakauteen, jonka leimaa digitaalinen teknologia ja digitaalisen liiketoiminnan innovaatiot.
Digitalisaatio on yhdessä yritysinnovaatioiden kanssa yksi talouden tulevaisuuden tärkeimmistä liiketoimintatrendeistä. Yritysten on kehitettävä digitaalisia strategioita ja keskityttävä digitaalisen muutoksen keskeisiin menestystekijöihin.

Tekoäly
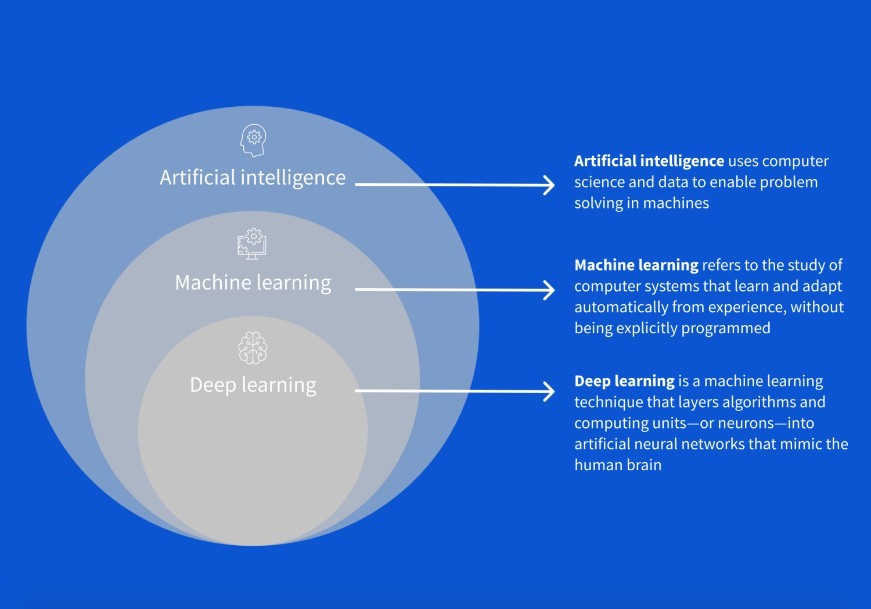
Tekoäly (artificial intelligence) on tiede, joka tekee tietokoneista kykeneviä jäljittelemään ihmisen älykkyyttä, kuten päätöksentekoa, tekstinkäsittelyä ja visuaalista havainnointia. Sen avulla pystytään rakentamaan koneita, jotka oppivat kokemuksista ja pystyvät suorittamaan ihmisille tyypillisiä tehtäviä niille syötetyn datan perusteella.

Tietokoneet opetetaan käsittelemään suuria tietomääriä, jotta ne pystyisivät simuloimaan datassa olevaa logiikkaa. Nykyään tekoälystä on tullut suositumpi, koska se automatisoi toistuvaa oppimista ja analysoi dataa syvällisemmin ja löytää tietomalleja uskomattomalla tarkkuudella. Tekoäly on laajempi ala, joka sisältää useita alakenttiä, kuten koneoppimisen, robotiikan ja tietokonenäön.

Koneoppiminen
Koneoppiminen (machine learning) on tietokoneen kyky oppia ilman eksplisiittistä ohjelmointia. Koneoppiminen käyttää suunniteltuja algoritmeja syöttödatan tulkitsemiseen, jotta se pystyisi tekemään tyydyttäviä ennustuksia. Koneoppimisen avulla koneet oppivat ja optimoivat toimintaansa, parantavat suorituskyykään ja kehittävät älykkyyttään ajan myötä, kun niihin syötetään uutta dataa.
Koneoppiminen on kyky valita merkittäviä ominaisuuksia kuvioiden tunnistamiseen, luokitteluun ja ennustamiseen olemassa olevista tiedoista johdettujen mallien perusteella. Koneoppiminen on tiedettä, jossa käytetään algoritmeja, jotka auttavat kaivamaan tietoa saatavilla olevista erittäin suurista datamääristä (Alpaydin, 2014).
Syväoppiminen
Syväoppiminen (deep learning) on koneoppimisen ala, joka perustuu syvien keinotekoisten neuroverkkojen (artificial neural networks (ANN)) opettamiseen käyttämällä suurta tietojoukkoa. Keinotekoiset neuroverkot ovat tietojenkäsittelymalleja, jotka jäljittelevät ihmisaivoja, joissa miljardit neuronit kommunikoivat keskenään sähköisiä ja kemiallisia signaaleja käyttäen.

Keinotekoiset neuroverkot toimivat jäljittelemällä matemaattisesti ihmisaivoja ja yhdistämällä useita keinotekoisia neuroneja monikerroksisesti. Verkko syvenee, kun siihen lisätään enemmän piilotettuja kerroksia. Syväoppimisessa valitaan ensin verkkoarkkitehtuuri ja sitten ominaisuudet puretaan automaattisesti syöttämällä harjoitustiedot yhdessä kohdeluokan (nimike) kanssa.
Koneoppimisen tyypit
Koneoppiminen (machine learning) käyttää suunniteltuja algoritmeja syöttödatan tulkitsemiseen, jotta se pystyisi tekemään tyydyttäviä ennustuksia. Koneoppimisen avulla koneet oppivat ja optimoivat toimintaansa, parantavat suorituskyykään ja kehittävät älykkyyttään ajan myötä, kun niihin syötetään uutta dataa.
Koneoppimisen merkitys kasvaa edelleen monissa organisaatioissa lähes kaikilla toimialueilla. Joitakin esimerkkisovelluksia koneoppimisesta käytännössä ovat:
- Potilaan sairaalaan paluun todennäköisyyden ennustaminen (takaisinotto) 30 päivän kuluessa kotiuttamisesta.
- Asiakkaiden segmentointi yhteisten ominaisuuksien tai ostokäyttäytymisen perusteella kohdennetussa markkinoinnissa.
- Kuponkien lunastuskurssien ennustaminen kampanjalle.
- Asiakkaiden tyytymättömyyden ennustaminen, jotta organisaatio voi suorittaa ennaltaehkäisevät toimenpiteet.
Pohjimmiltaan kaikki nämä tehtävät pyrkivät oppimaan datasta. Kunkin skenaarion ratkaisemiseksi voimme käyttää määritettyjä ominaisuuksia algoritmin opettamiseen ja näkemyksen tuottamiseen.
Nämä algoritmit eli oppijat voidaan luokitella oppimisen aikana tarvittavan valvonnan määrän ja tyypin mukaan. Toivottu oppimistehtävä määrittää, millaista oppimista käytämme.
Miten tietokone tietää, parantaako se suoritustaan vai ei, ja miten se osaa parantaa? Erilaiset vastaukset näihin kysymyksiin tuottavat erilaisia koneoppimistyyppejä:
- Algoritmille voidaan kertoa oikean vastauksen ongelmaan, jotta se toimii oikein ensi kerralla. Toivottavaa kuitenkin on, että sille on kerrottava vain muutama oikea vastaus, ja myöhemmin se voi selvittää, miten saada oikeat vastaukset muihin ongelmiin (yleistäminen, induktio, induktiivinen päättely).
- Vaihtoehtoisesti algoritmille voidaan kertoa, oliko vastaus oikea vai ei, mutta ei sitä, miten löytää oikea vastaus, niin että sen on etsittävä oikea vastaus itse.
- Toinen ratkaisu on antaa pisteitä vastauksesta sen mukaan, kuinka oikea se on, eikä vain määrittää vastausta ”oikeaksi” tai ”vääräksi”.
- Voi myös olla tilanteita, joissa ehkä ei ole tiedossa oikeita vastauksia ja toivotaan, että algoritmi löytää syöttötietojen välisiä yhteyksiä.
Koneoppimiseen on olemassa useita algoritmeja. Ne luokitellaan yleisesti seuraavasti:
- Ohjattu, joka rakentaa ennustavia malleja todennäköisten tulevien tulosten ennustamiseen (Supervised)
- Ohjaamaton, joka rakentaa kuvailevia malleja tulosten ymmärtämiseen (Unsupervised)
- Vahvistettu
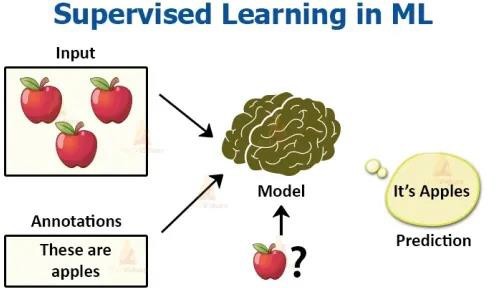
Ohjattu oppiminen
Ohjatussa oppimisessa annetaan oppimisesimerkkejä, joissa on oikeat vastaukset (tavoitteet), ja tämän oppimisjoukkoon perustuen algoritmi yleistää vastaamaan oikein kaikkiin mahdollisiin syötteisiin. Tätä kutsutaan myös esimerkistä opettelemiseksi (learning from examplars).
Ohjaamaton oppiminen
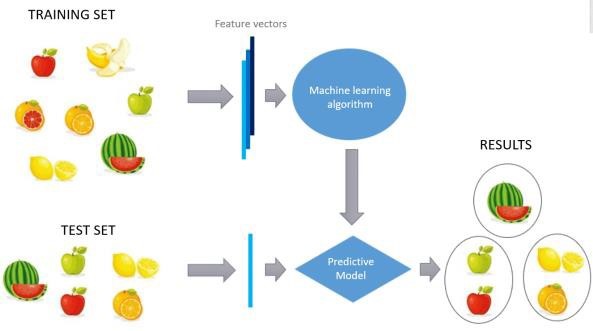
Ohjaamattomassa oppimisessa oikeita vastauksia ei tarjota, mutta sen sijaan algoritmi yrittää tunnistaa samankaltaisuudet syötteiden välillä niin, että syötteet, joilla on jotain yhteistä, luokitellaan yhteen.
Vahvistettu oppiminen
Vahvistettu oppiminen on jossain ohjatun ja ohjaamattoman oppimisen väliltä. Algoritmille kerrotaan, kun vastaus on väärä, mutta sille ei kerrota, miten se korjataan.
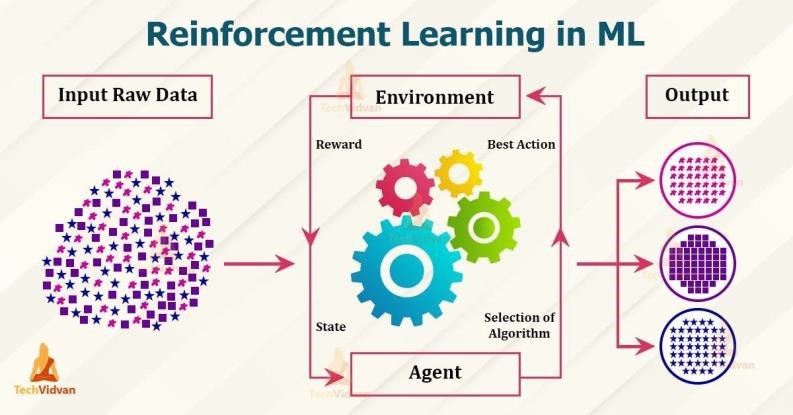
Algoritmin on tutkittava ja kokeiltava erilaisia mahdollisuuksia, kunnes se selvittää, miten saadaan oikea vastaus. Vahvistettua oppimista kutsutaan joskus oppimiseksi kriitikon kanssa tämän ohjauksen vuoksi, joka antaa pisteitä vastauksista, mutta ei ehdota parannuksia.
Evoluutio-oppiminen
Biologista evoluutiota voidaan pitää oppimisprosessina, koska biologiset organismit sopeutuvat parantamaan eloonjäämisastettaan ja mahdollisuutta saada jälkeläisiä elinympäristössään. Tämän mallin soveltamiseksi tietokoneohjelmissa käytetään hyvyysarvoa, joka mittaa kuinka hyvä tai lähellä hyväksyttävää arvoa tietty ratkaisu on.
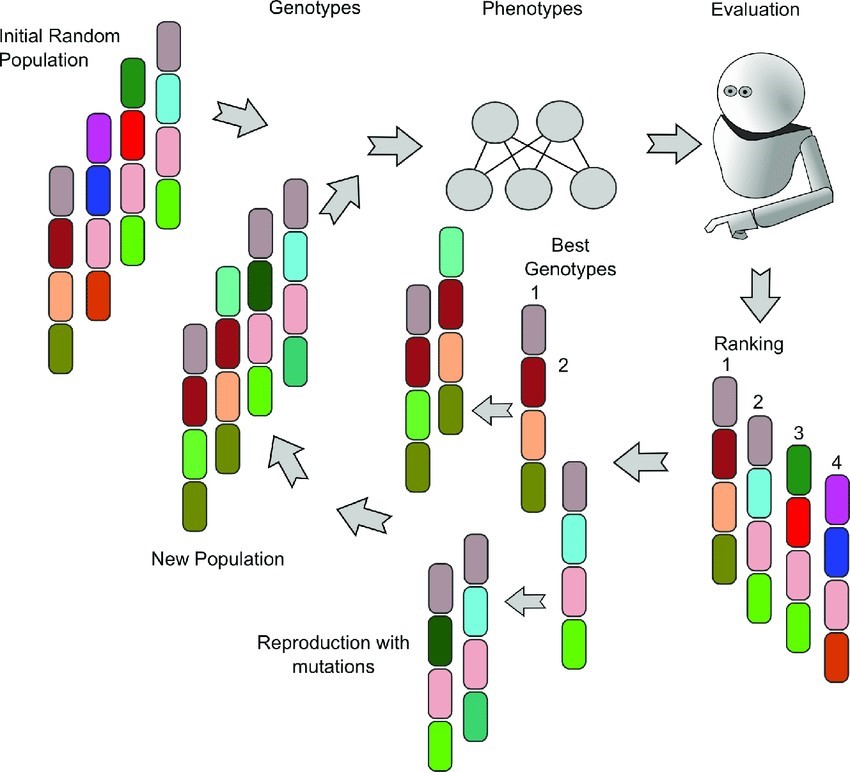
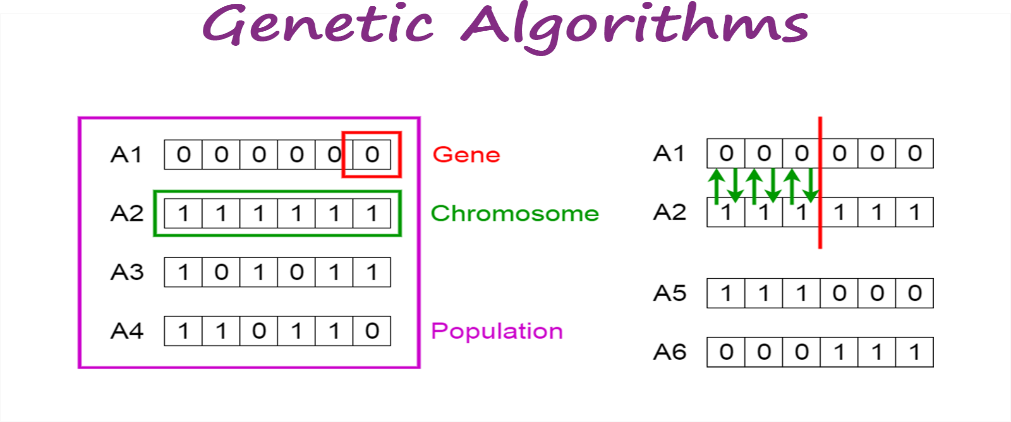
Evoluutioalgoritmit (Evolutionary algorithms) käyttävät ajatusta populaatioista, joita jalostetaan siittämällä yksilöitä keskenään ja soveltamalla geneettisiä operaattoreita, kuten risteytystä (crossover) ja mutaatiota (mutation), toivoen, että nämä johtavat parempien yksilöiden tuottamiseen.
Luokittelu
Luokittelu (Classification) on ohjattu oppimisprosessi, jossa luokista käytetään joskus nimitystä tavoitteet/nimikkeet tai luokat, joilla ennustetaan annettujen syötearvojen luokkaa.
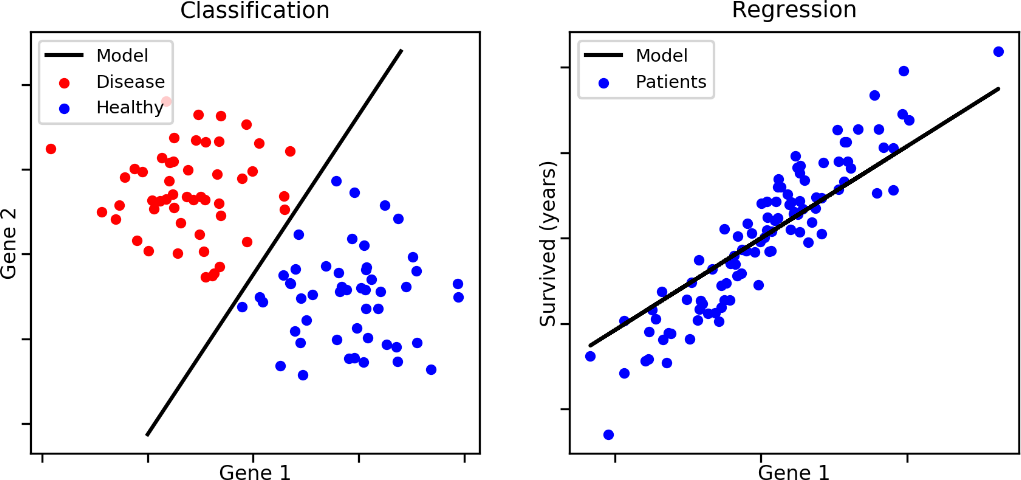
Koneoppimisohjelmat vetävät luokittelussa johtopäätöksiä annetuista arvoista ja löytävät luokan, johon uudet syötearvot viittaavat. Esimerkiksi Pullon palautuslaite tutkii syötetyt asiat, luokittelee niitä ”pulloksi” ja ”ei pulloksi”.
Klusterointi
Merkitsemättömien tietojen ryhmittelemistä kutsutaan klusterointiksi (Clustering). Merkitsemättömien tietojen klusterointi perustuu ohjaamattomaan koneoppimiseen. Klusterointia käytetään samankaltaisten esiintymien ryhmittelemiseen, jotta voidaan selvittää auttaako ryhmittely käytettyjen ominaisuuksien (features, attributes) lukumäärän vähentämistä.
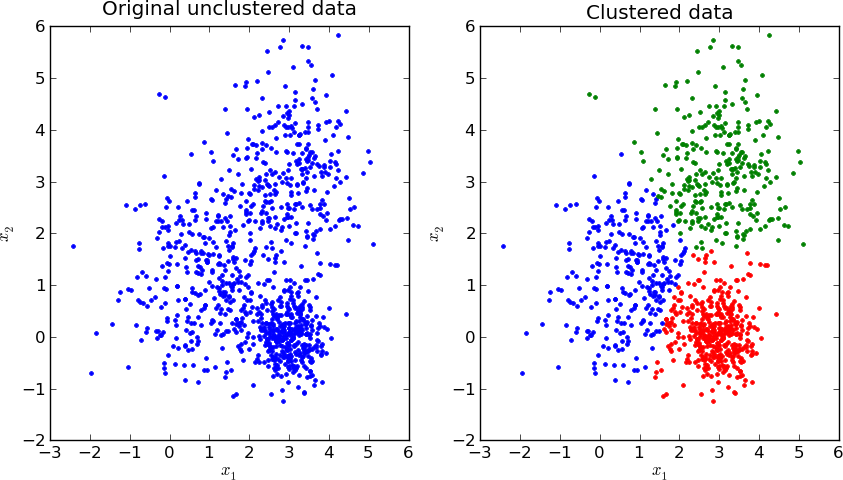
Näytteiden samankaltaisuutta voidaan mitata yhdistämällä niiden ominaisuustietoja mittariksi, jota kutsutaan samankaltaisuusmittariksi (similarity measure). Kun jokainen näyte määritetään yhdellä tai kahdella ominaisuudella, samankaltaisuutta on helppo mitata.
Samanlaisia tuotteita voidaan esimerkiksi ryhmitellä niiden tuottajatietojen perusteella. Ominaisuuksien määrän kasvaessa samankaltaisuuden mittaaminen muuttuu monimutkaisemmaksi.
Klusteroinnilla on lukuisia käyttötarkoituksia eri toimialoilla, kuten:
- Poikkeaman havaitseminen (tunnistaa tietojoukon normaalista jakaumasta poikkeavat arvot, tapahtumat ja/tai havainnot)
- Kuvan segmentointi (digitaalisen kuvan jakaminen useisiin segmentteihin; kuvapistejoukot, joita kutsutaan myös kuvaobjekteiksi)
- Markkinoiden segmentointi (tulevien ostajien ryhmitteleminen segmentteihin, joilla on yhteisiä tarpeita ja jotka vastaavat samalla tavalla markkinointitoimiin)
- Sosiaalisen verkoston analysointi (sosiaalisten suhteiden kartoitus ja mittaaminen rikollisepäiltyjen sosiaalisten verkostojen löytämiseksi, analysoimis ja visualisoimiseksi)



